Loading collection...
🎓
LLM Training Vocabulary
Methods and concepts for training large language models
10 words
All 10 Words

pre-training
initial training on vast text data to learn language patterns before task-specific fine-tuning
“Pre-training on internet text gives the model broad world knowledge.”

fine-tuning
/ˈfaɪn ˌtuːnɪŋ/additional training on specific data to adapt a pre-trained model for particular tasks
“Fine-tuning on medical texts improved the model's diagnostic suggestions.”

RLHF
/ˌɑːr el eɪtʃ ˈef/reinforcement learning from human feedback—training models using human preference judgments
“RLHF shaped the model's helpfulness by learning from human ratings of responses.”

supervised learning
/ˌsuːpərˌvaɪzd ˈlɜːrnɪŋ/training on labeled examples where correct outputs are provided
“Supervised learning on question-answer pairs teaches the model to respond helpfully.”

self-supervised learning
/ˌself ˌsuːpərˌvaɪzd ˈlɜːrnɪŋ/training where labels are derived from the data itself, like predicting masked words
“Self-supervised learning on next-token prediction requires no human labeling.”

loss function
/ˈlɒs ˌfʌŋkʃən/a mathematical measure of how wrong the model's predictions are, minimized during training
“Cross-entropy loss measures how different the predicted token distribution is from the actual next token.”

gradient descent
/ˌɡreɪdiənt dɪˈsent/an optimization algorithm that iteratively adjusts parameters to minimize loss
“Gradient descent slowly nudges billions of parameters toward better predictions.”
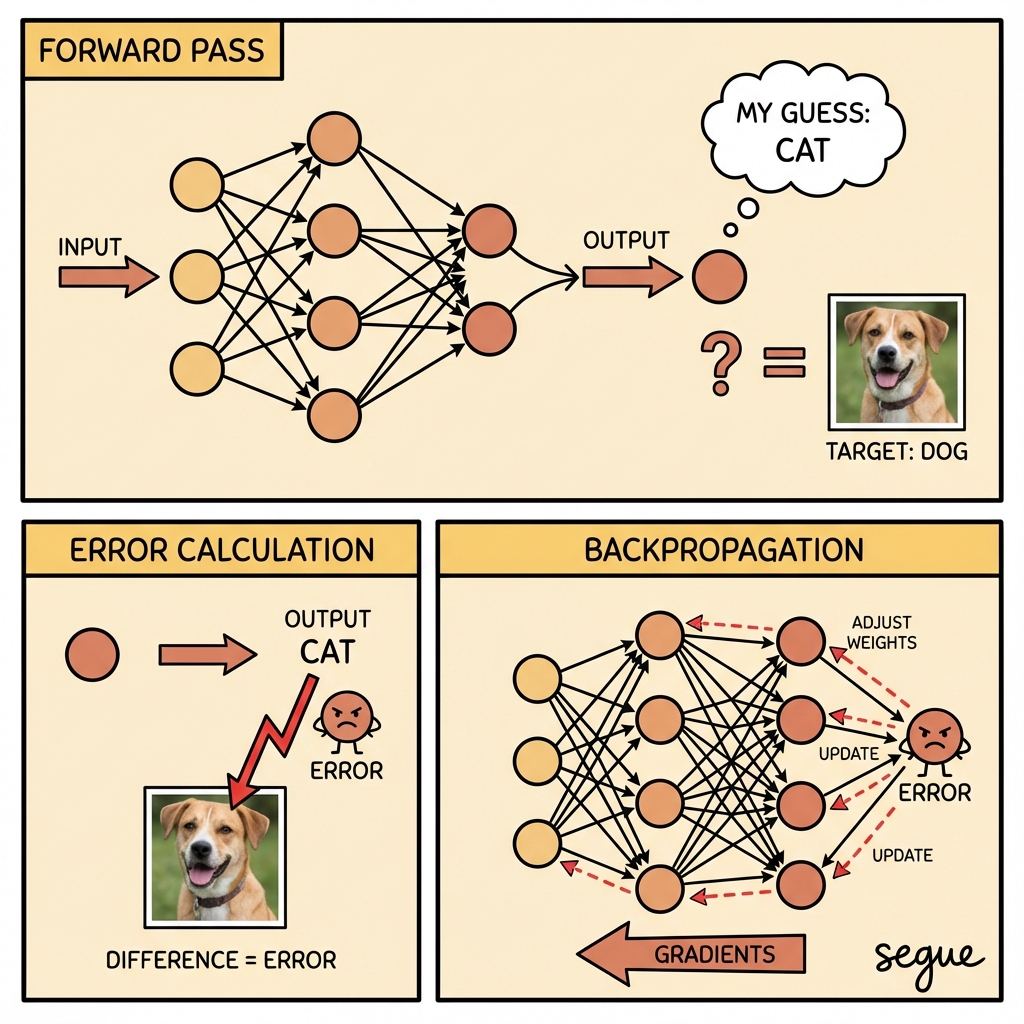
backpropagation
/ˌbækˌprɒpəˈɡeɪʃən/the algorithm for computing gradients by propagating errors backward through the network
“Backpropagation calculates how each weight contributed to the prediction error.”

overfitting
/ˈoʊvərˌfɪtɪŋ/when a model memorizes training data rather than learning generalizable patterns
“Overfitting caused the model to excel on training examples but fail on new ones.”
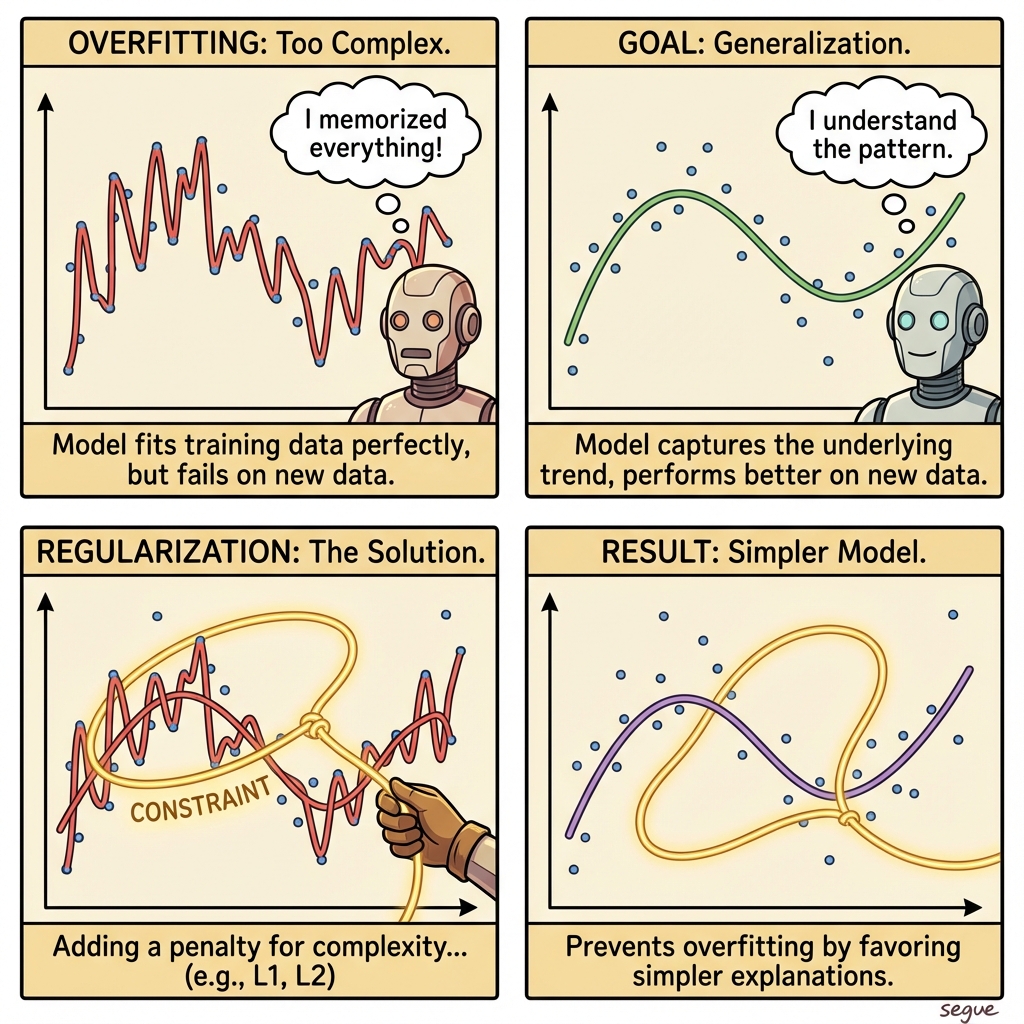
regularization
/ˌreɡjʊləraɪˈzeɪʃən/techniques to prevent overfitting by constraining model complexity
“Dropout regularization randomly disables neurons during training to improve generalization.”
More from Artificial Intelligence
Explore other vocabulary categories in this collection.