Loading collection...
⚡
LLM Inference Vocabulary
How language models generate responses at runtime
10 words
All 10 Words
inference
/ˈɪnfɝəns/the process of using a trained model to generate predictions or outputs
“Inference latency determines how quickly the chatbot can respond.”

temperature
/ˈtɛmpɝətʃɝ/a sampling parameter that flattens or sharpens the next-token probability distribution
“Lowering temperature usually favors higher-probability tokens, but does not guarantee identical output across requests.”

sampling
/ˈsæmpɫɪŋ/randomly selecting the next token from the probability distribution rather than always choosing the most likely
“Top-p sampling only considers tokens whose cumulative probability exceeds a threshold.”
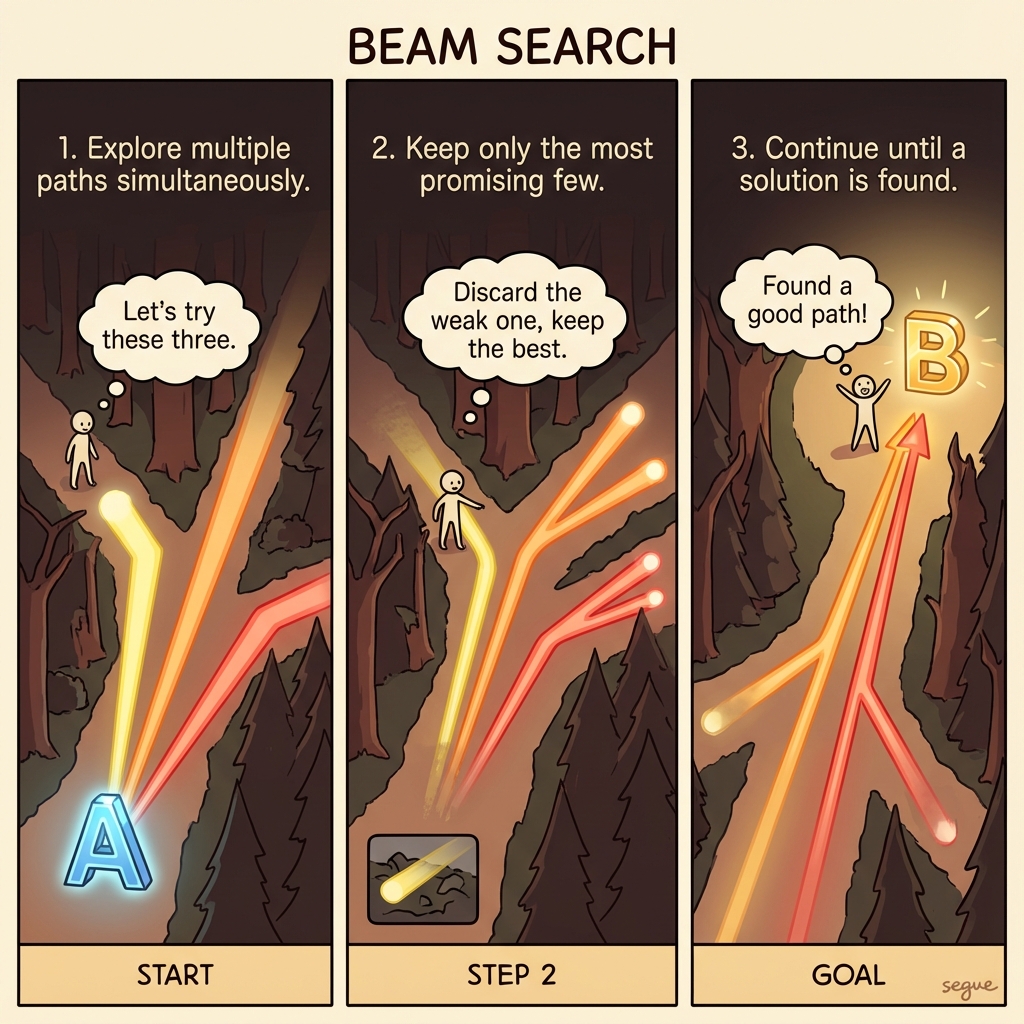
beam search
/ˈbiːm ˌsɜːrtʃ/a search algorithm that explores multiple candidate sequences simultaneously
“Beam search with width 5 tracks the five most promising response paths.”

greedy decoding
/ˌɡriːdi dɪˈkoʊdɪŋ/always selecting the highest probability token at each step
“Greedy decoding is fast but may miss better overall sequences.”

top-k sampling
/ˌtɒp ˈkeɪ ˌsæmplɪŋ/sampling only from the k most likely next tokens
“Top-k sampling with k=50 prevents rare, nonsensical tokens from being selected.”

nucleus sampling
/ˈnjuːkliəs ˌsæmplɪŋ/sampling from tokens comprising the top cumulative probability mass (top-p)
“Nucleus sampling with p=0.95 adapts vocabulary size to context certainty.”
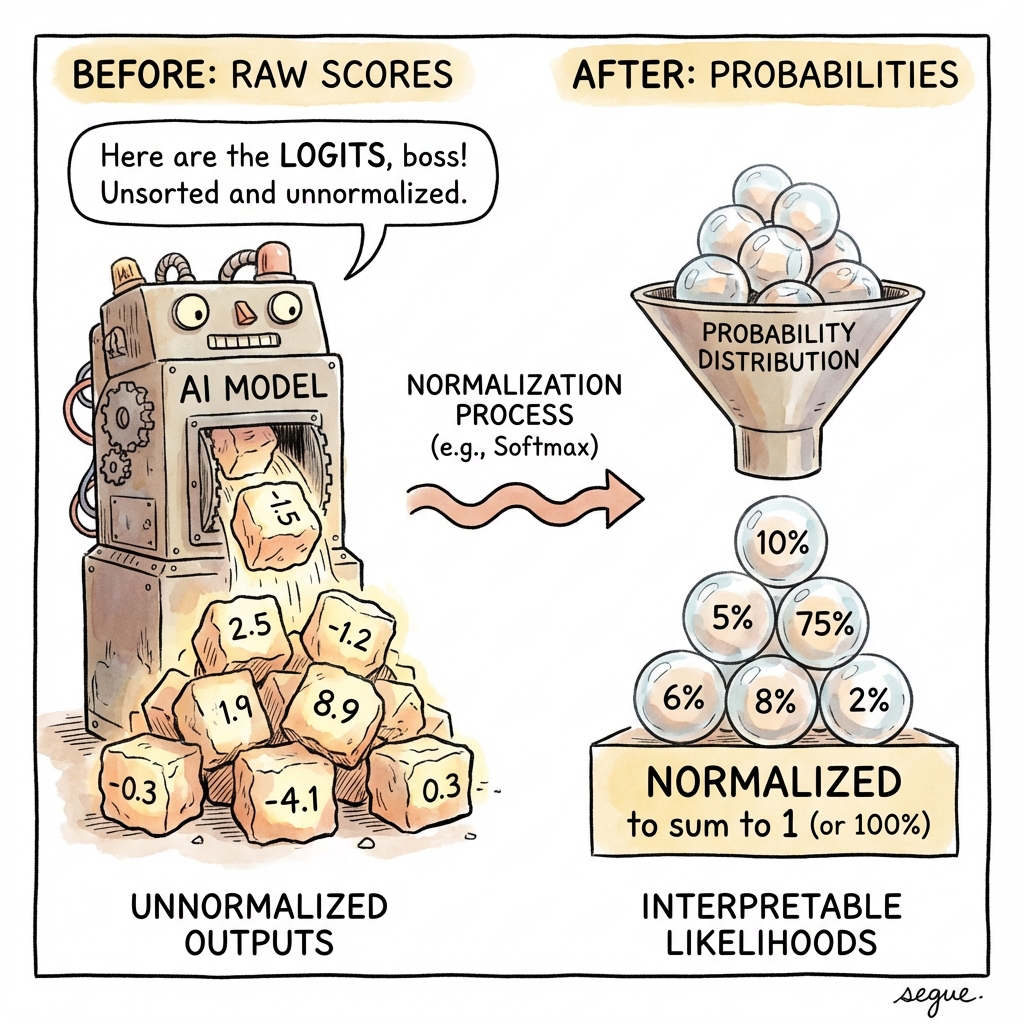
logits
/ˈloʊdʒɪts/raw, unnormalized scores output by the model before conversion to probabilities
“Logits are converted to probabilities using the softmax function.”

softmax
/ˈsɔːftmæks/a function that converts logits into a probability distribution summing to one
“Softmax exponentiates each logit and normalizes so all probabilities sum to 1.”

KV cache
/ˌkeɪ ˈviː ˌkæʃ/cached key-value pairs from previous tokens to speed up autoregressive generation
“The KV cache avoids recomputing attention for earlier tokens at each step.”
More from Artificial Intelligence
Explore other vocabulary categories in this collection.